

Cloudberry Database 架构介绍
本文介绍 Cloudberry Database 的产品架构以及内部模块的实现机制。
在大多数情况下,Cloudberry Database 在 SQL 支持、功能、配置选项和最终用户功能方面与 PostgreSQL 非常相似。数据库用户与 Cloudberry Database 数据库的交互体验,非常接近与单机 PostgreSQL 进行交互。
Cloudberry Database 采用 MPP 架构技术,通过在多个服务器或主机之间分配数据和处理工作负载来存储和处理大量数据。
MPP 也称为大规模并行处理架构,是指具有多台主机的系统,这些主机协作执行同一操作。每台主机都有自己的处理器、内存、磁盘、网络资源和操作系统。Cloudberry Database使用这种高性能的系统架构来分配海量数据的负载,并且可以并行使用系统的所有资源来处理查询。
从用户角度来看,Cloudberry Database 是一个完备的关系数据库管理系统 (RDBMS)。从物理层面来看,它内含多个 PostgreSQL 实例。为了实现多个独立 PostgreSQL 实例的分工和合作,Cloudberry Database ��在不同层面对数据存储、计算、通信和管理进行了分布式集群化处理。Cloudberry Database 虽然是一个集群,然而对用户而言,它封装了所有分布式的细节,为用户提供了单个逻辑数据库。这种封装极大地解放了开发人员和运维人员的工作。
Cloudberry Database 架构图如下所示:
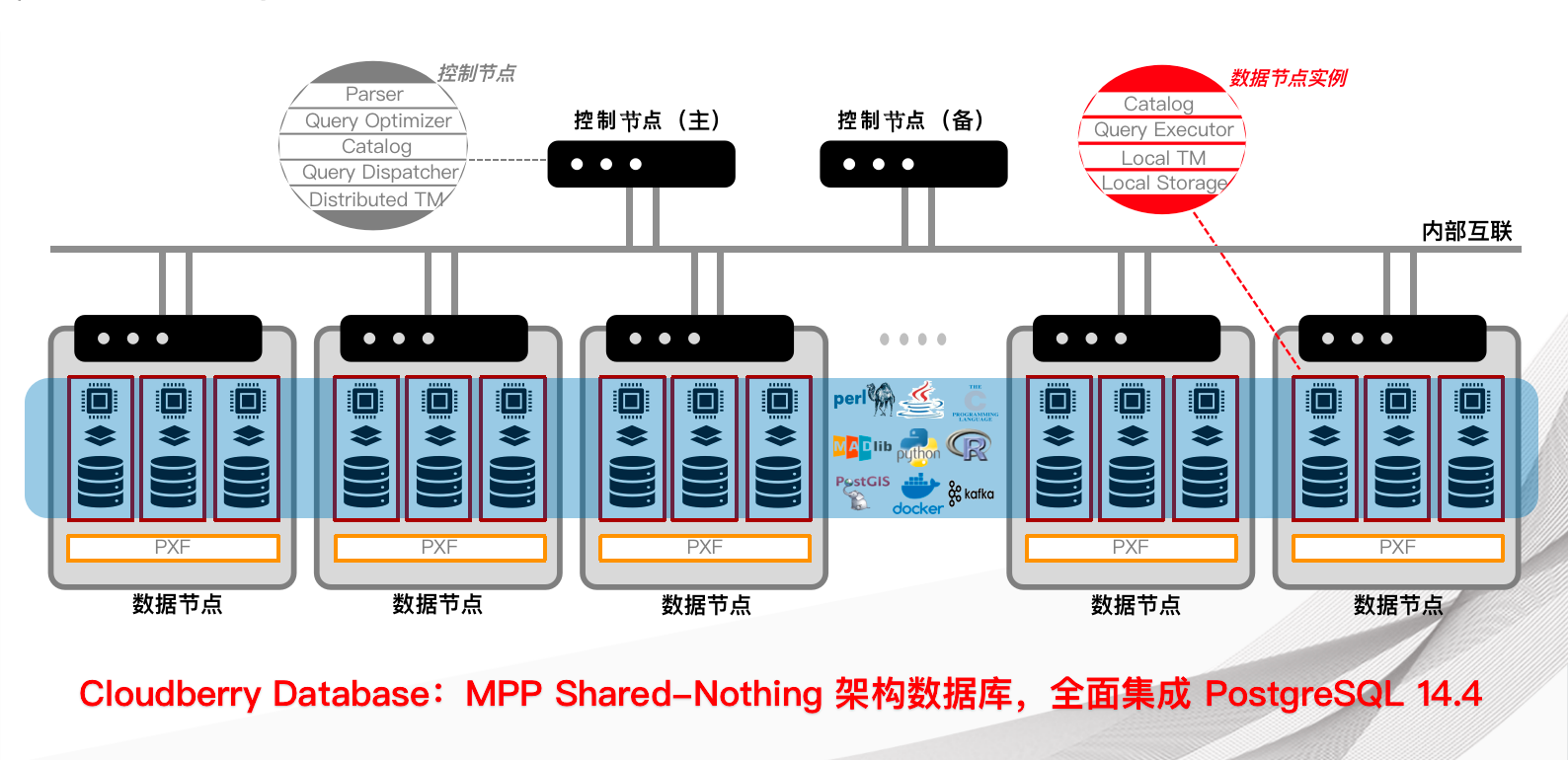
-
控制节点 (Coordinator) 是 Cloudberry Database 数据库系统的入口,它接受客户端连接和 SQL 查询,并将工作分配给数据节点实例。用户与 Cloudberry Database 进行交互,使用客户端程序(例如 psql)或应用程序编程接口(API)(例如 JDBC、ODBC 或 libpq PostgreSQL C API)连接到控制节点。
- 控制节点是全局系统目录所在的位置,全局系统目录是一组系统表,其中包含有关 Cloudberry Database 数据库系统本身的元数据。
- 控制节点不包含任何用户数据,数据只保存在数据节点实例上。
- 控制节点对客户端连接进行身份验证,处理传入的 SQL 命令,在数据节点之间分配工作负载,协调每个数据节点返回的结果,并将最终结果呈现给客户端程序。
- Cloudberry Database 使用预写日志记录(WAL)进行控制节点/Standby 镜像。在基于 WAL 的日志记录中,所有修改都将在写入磁盘之前先写日志,以确保任何进程内操作的数据完整性。
-
数据节点 (Segment) 实例是独立的 Postgres 进程,每个数据节点存储一部分数据并执行相应部分查询。当用户通过控制节点连接到数据库并提交查询请求时,会在每个数据节点创建进程来处理查询。用户定义的表及其索引分布在 Cloudberry Database 中的�所有可用数据节点中,每个数据节点都包含数据的不同部分,不同部分数据处理的进程在相应的数据节点中运行。用户通过控制节点与数据节点进行交互,数据节点在称为数据节点主机的服务器上运行。
数据节点主机通常执行 2 到 8 个数据节点,具体取决于处理器、内存、存储、网络接口和工作负载。数据节点主机的需要平衡配置,因为 Cloudberry Database获得最佳性能的关键是将数据和工作负载平均分配到数据节点中,以便所有数据节点同时开始处理一项任务并同时完成工作。
-
内部互联 (Interconnect) 是 Cloudberry Database 系统架构中的网络层。内部互联是指控制节点、数据节点通信所依赖的网络基础架构,使用标准的以太网交换结构。
出于性能原因,建议使用 10 GB 或更快的网络。默认情况下,内部互联模块使用带有流控制(UDPIFC) 的 UDP 协议来实现通信,以通过网络发送消息。Cloudberry Database 执行的数据包验证超出了 UDP 所提供的范围,这意味着可靠性等同于使用 TCP 协议,并且性能和可伸缩性超过了 TCP 协议。 如果将内部互联改为使用 TCP 协议,则 Cloudberry Database 的可伸缩性限制为 1000 个数据节点。使用 UDPIFC 作为默认协议时,此限制不适用。
-
Cloudberry Database 使用多版本控制 (Multiversion Concurrency Control/MVCC) 保证数据一致性。这意味着在查询数据库时,每个事务看到的只是数据的快照,其确保当前的事务不会看到其他事务在相同记录上的修改。据此为数据库的每个事务提供事务隔离。
MVCC 以避免给数据库事务显式锁定的方式,最大化减少锁争用以确保多用户环境下的性能。在并发控制方面,使用 MVCC 而不是使用锁机制的最大优势是,MVCC 对查询(读)的锁与写的锁不存在冲突,并且�读与写之间从不互相阻塞。

