Cloudberry Database Architecture
This document introduces the product architecture and the implementation mechanism of the internal modules in Cloudberry Database.
In most cases, Cloudberry Database is similar to PostgreSQL in terms of SQL support, features, configuration options, and user functionalities. Users can interact with Cloudberry Database in a similar way to how they interact with a standalone PostgreSQL system.
Cloudberry Database uses MPP (Massively Parallel Processing) architecture to store and process large volumes of data, by distributing data and computing workloads across multiple servers or hosts.
MPP, known as the shared-nothing architecture, refers to systems with multiple hosts that work together to perform a task. Each host has its own processor, memory, disk, network resources, and operating system. Cloudberry Database uses this high-performance architecture to distribute data loads and can use all system resources in parallel to process queries.
From users' view, Cloudberry Database is a complete relational database management system (RDBMS). In a physical view, it contains multiple PostgreSQL instances. To make these independent PostgreSQL instances work together, Cloudberry Database performs distributed cluster processing at different levels for data storage, computing, communication, and management. Cloudberry Database hides the complex details of the distributed system, giving users a single logical database view. This greatly eases the work of developers and operational staff.
The architecture diagram of Cloudberry Database is as follows:
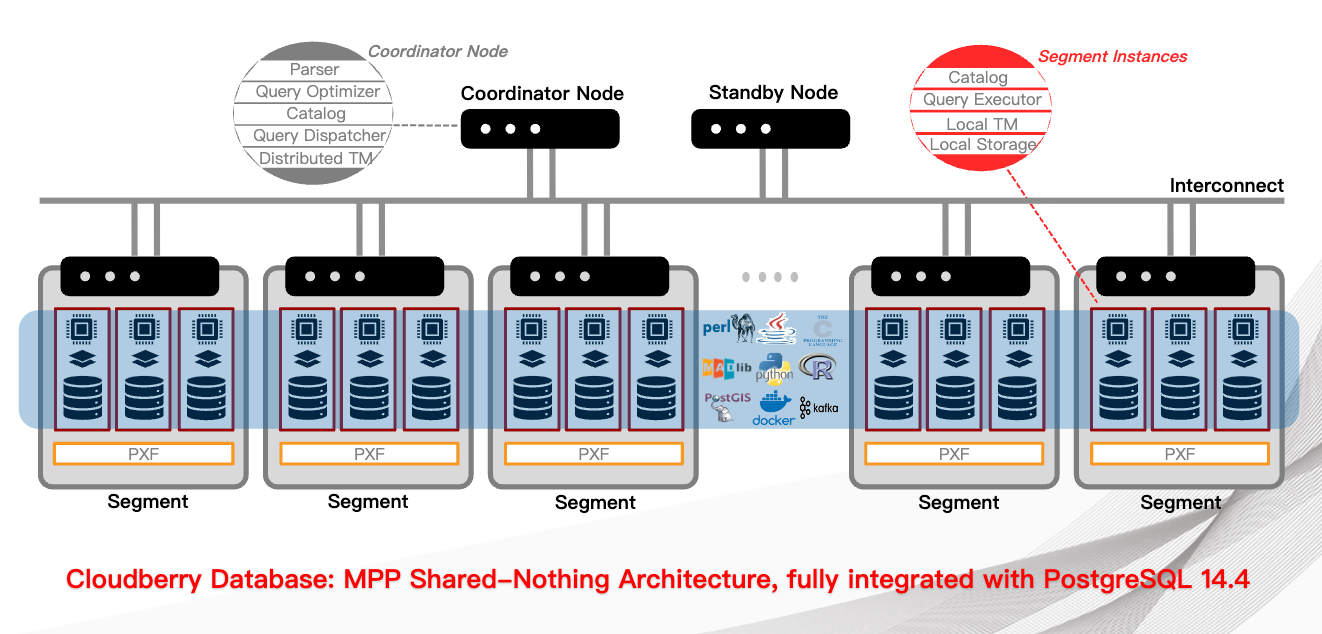
-
Coordinator node (or control node) is the gateway to the Cloudberry Database system, which accepts client connections and SQL queries, and allocates tasks to data node instances. Users interact with Cloudberry Database by connecting to the coordinator node using a client program (such as psql) or an application programming interface (API) (such as JDBC, ODBC, or libpq PostgreSQL C API).
- The coordinator node acts as the global system directory, containing a set of system tables that record the metadata of Cloudberry Database.
- The coordinator node does not store user data. User data is stored only in data node instances.
- The coordinator node performs authentication for client connections, processes SQL commands, distributes workload among segments, coordinates the results returned by each segment, and returns the final results to the client program.
- Cloudberry Database uses Write Ahead Logging (WAL) for coordinator/standby mirroring. In WAL-based logging, all modifications are first written to a log before being written to the disk, which ensures the data integrity of in-process operations.
-
Segment (or data node) instances are individual Postgres processes, each storing a portion of the data and executing the corresponding part of the query. When a user connects to the database through the coordinator node and submits a query request, a process is created on each segment node to handle the query. User-defined tables and their indexes are distributed across the available segments, and each segment node contains distinct portions of the data. The processes of data processing runs in the corresponding segment. Users interact with segments through the coordinator, and the segment operate on servers known as the segment host.
Typically, a segment host runs 2 to 8 data nodes, depending on the processor, memory, storage, network interface, and workload. The configuration of the segment host needs to be balanced, because evenly distributing the data and workload among segments is the key to achieving optimal performance with Cloudberry Database, which allows all segments to start processing a task and finish the work at the same time.
-
Interconnect is the network layer in the Cloudberry Database system architecture. Interconnect refers to the network infrastructure upon which the communication between the coordinator node and the segments relies, which uses a standard Ethernet switching structure.
For performance reasons, a 10 GB or faster network is recommended. By default, the Interconnect module uses the UDP protocol with flow control (UDPIFC) for communication to send messages through the network. The data packet verification performed by Cloudberry Database exceeds the scope provided by UDP, which means that its reliability is equivalent to using the TCP protocol, and its performance and scalability surpass the TCP protocol. If the Interconnect is changed to the TCP protocol instead, the scalability of Cloudberry Database is limited to 1000 segments. This limit does not apply when UDPIFC is used as the default protocol.
-
Cloudberry Database uses Multiversion Concurrency Control (MVCC) to ensure data consistency. When querying the database, each transaction only sees a snapshot of the data, ensuring that current transactions do not see modifications made by other transactions on the same records. In this way, MVCC provides transaction isolation in the database.
MVCC minimizes lock contention to ensure performance in a multi-user environment. This is done by avoiding explicit locking for database transactions.
In concurrency control, MVCC does not introduce conflicts for query (read) locks and write locks. In addition, read and write operations do not block each other. This is the biggest advantages of MVCC over the lock mechanism.

